
1. 当我们想要优化索引时,首先会想到的可能是:优化索引的接口性能。{是的}{对的}{没错},索引优化的成本是最低的。当你查看线上日志或监控报告时,可能会发现某个接口所使用的某个 SQL 语句所需的时间较长。此时你可能会有以下疑问:这条SQL语句有没有加索引?索引
是否已经生效了?MySQL 是否选择了错误的索引?在项目中,很常见的问题是在SQL语句中忘了为where条件和order by字段加上索引。
项目初期,由于表中的数据量较少,添加索引对SQL查询性能的影响不明显。随着业务的发展,表中的数据量不断增加,最终不得不添加索引。可以使用以下命令来查看:SHOW INDEX FROM `order`; 这样可以单独查看某张表的索引情况。可以使用以下命令来获取表的建表语句以及其中的索引信息:

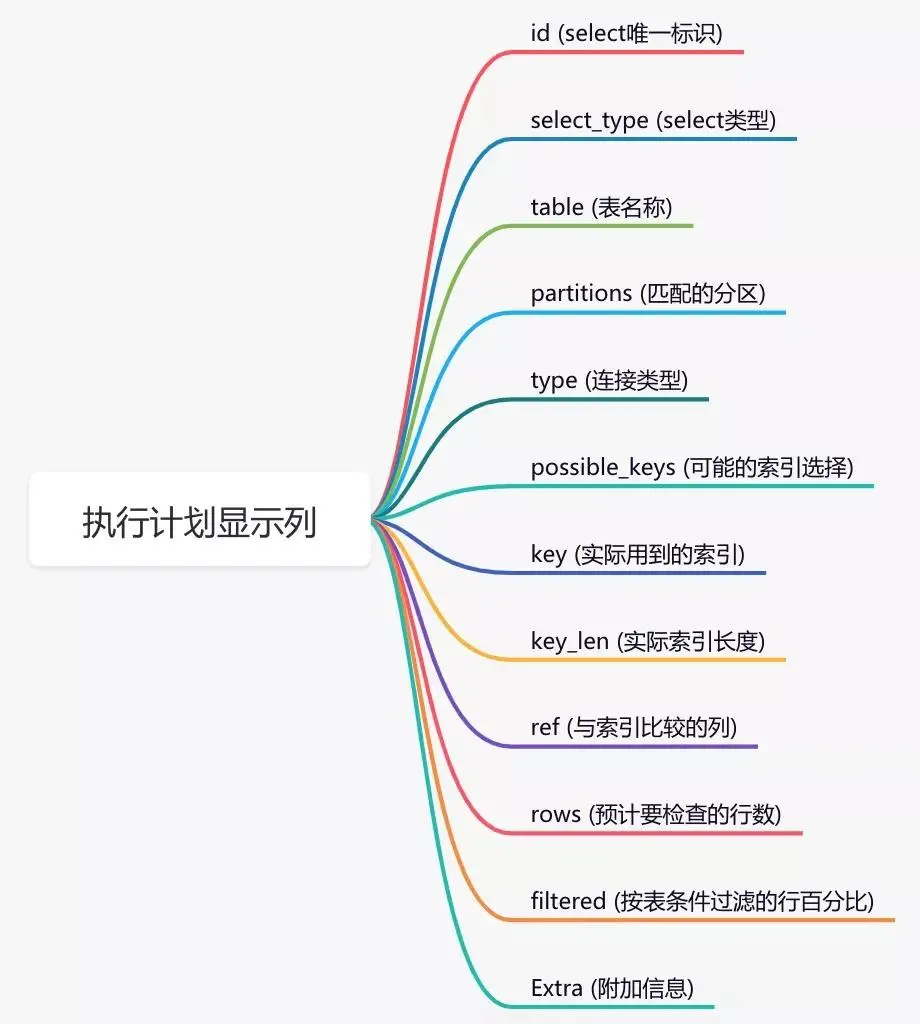
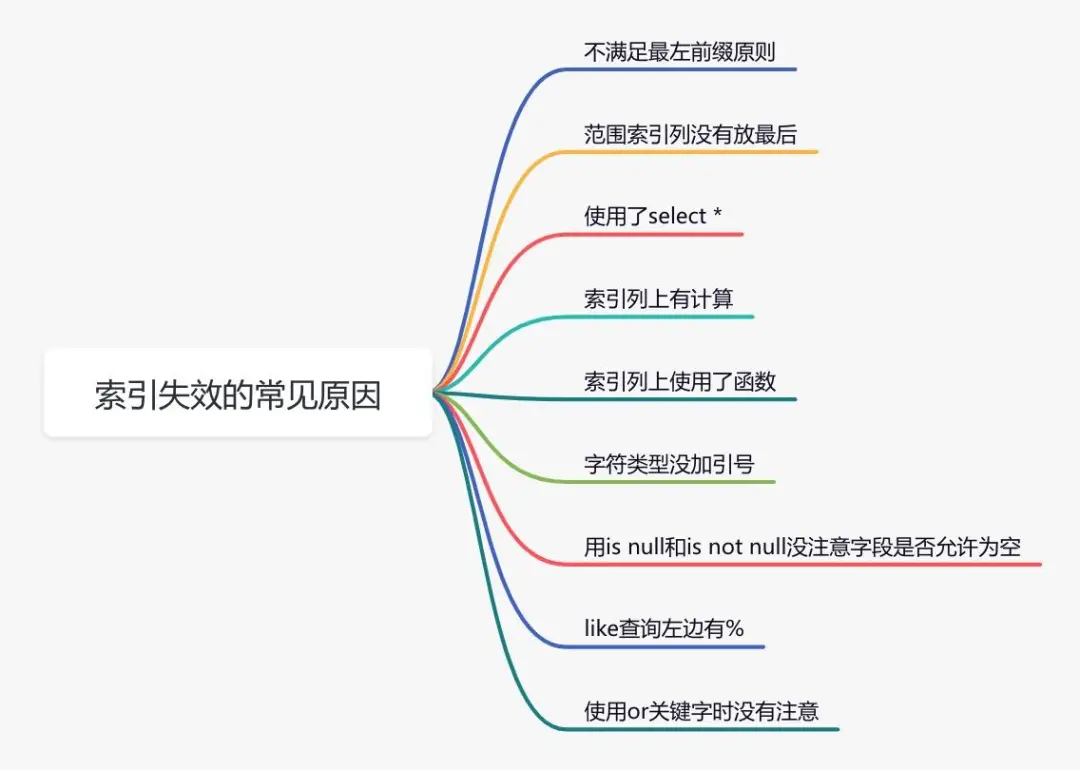
show create table `order`;使用ALTER TABLE命令可以添加索引:ALTER TABLE `order` ADD INDEX idx_name(name);同时,也可以使用CREATE INDEX命令添加索引:CREATE INDEX idx_name ON `order`(name);但需要注意的是,不能使用命令修改已有的索引。目前在 MySQL 中修改索引的唯一方法是先删除原有的索引,然后再重新添加新的索引。删除索引可以使用 DROP INDEX 命令:\n```sql\nALTER TABLE `order` DROP INDEX idx_name;\n```\n也可以使用 DROP INDEX 命令:\n```sql\nDROP INDEX idx_name ON `order`;\n```\n1.2 索引没有生效\n通过上述命令我们可以确认索引存在,但它是否生效了呢?这个时候,你心里可能会产生这样的疑问。那么,怎样才能确认索引是否生效呢?答:可以使用explain命令来查看MySQL的执行计划,这将显示索引的使用情况。示例:\n例如,在订单表中选择所有数据,其中订单编号为'002':\nSELECT * FROM `order` WHERE code='002';\n结果:\n通过这几列可以判断索引的使用情况,执行计划中列的含义如下图所示:\n如果你想深入了解explain的详细用法,可以参考我另一篇文章《explain | 索引优化的绝世好剑,你真的会用吗?》。》说实话,SQL语句没有使用索引,除了可能没有创建索引之外,最有可能的原因是索引失效了。索引失效常见原因如下:\n如果不是上述原因,则需要进一步排查其他可能原因。1.3 选择错误的索引后,你是否遇到过这样的情况:明明是相同的sql语句,只是入参不同而已。有时候使用索引a,有时候却使用索引b?是的,有时候MySQL会误选索引。如果需要,可以使用force index来强制SQL查询使用特定的索引。关于为什么MySQL会选择错误的索引,会在后面有专门的文章介绍,现在先保留一些悬念。
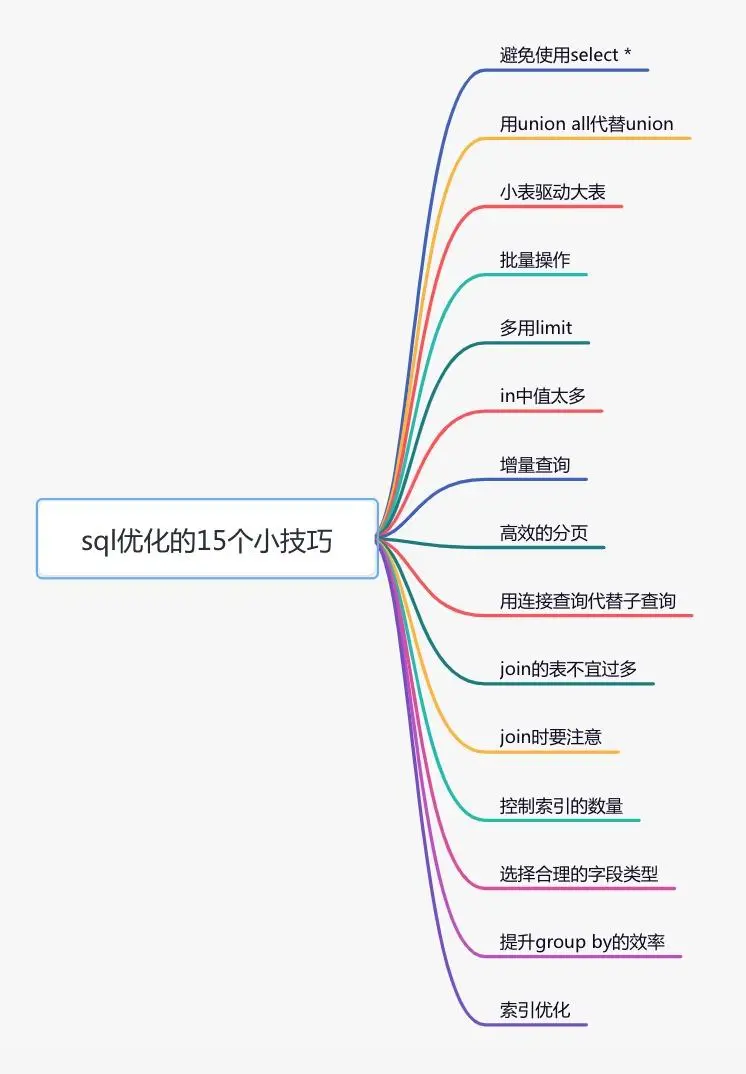
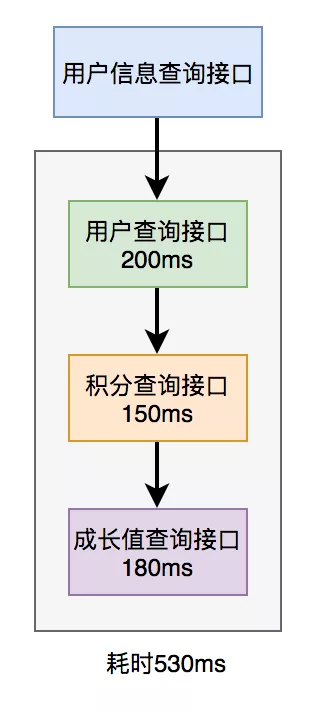
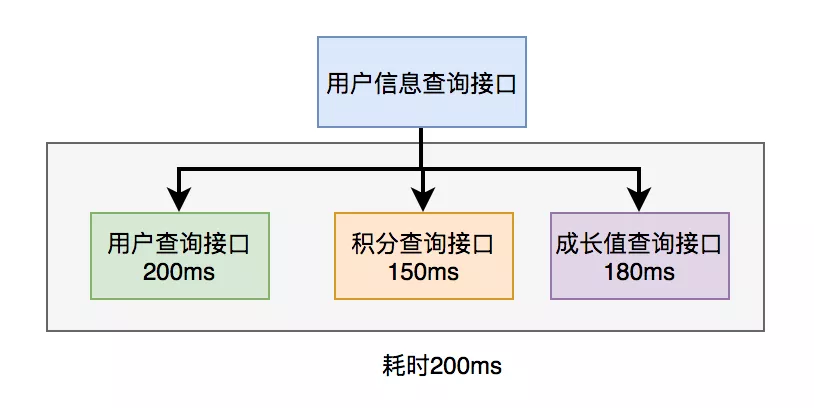
2. SQL优化如果索引优化后仍未见明显效果。现在我们尝试对该 SQL 语句进行优化,因为相对于 Java 代码而言,它的修改成本更小。下面,我将列举15个有关sql优化的小技巧:这些技巧已经在我之前的文章中进行了详细介绍,所以在这里我就不再深入解释了。如果你想了解更多详细内容,可以参考我写的另一篇文章《聊聊SQL优化的15个小技巧》。我相信读完之后,你会收获颇丰。3. 远程调用\n在许多情况下,我们需要在一个接口中调用其他服务的接口。比如说,在一个用户信息查询的场景中,需要返回用户的姓名、性别、等级、头像、积分和成长值等信息。在用户服务中包含用户名、性别、等级和头像,积分在积分服务中,成长值在成长值服务中。为了统一返回这些数据的汇总,需要再提供一个外部接口服务。因此,用户信息查询接口需要调用用户查询接口、积分查询接口以及成长值查询接口,最终汇总数据并统一返回。调用过程如下图所示:
调用远程接口总耗时为530毫秒,其中包括200毫秒的执行时间、150毫秒的传输时间和180毫秒的处理时间。显然,这种串行调用远程接口的性能非常低下,因为总的耗时是所有远程接口耗时之和。如何才能优化远程接口的性能呢?
3.1 并发调用
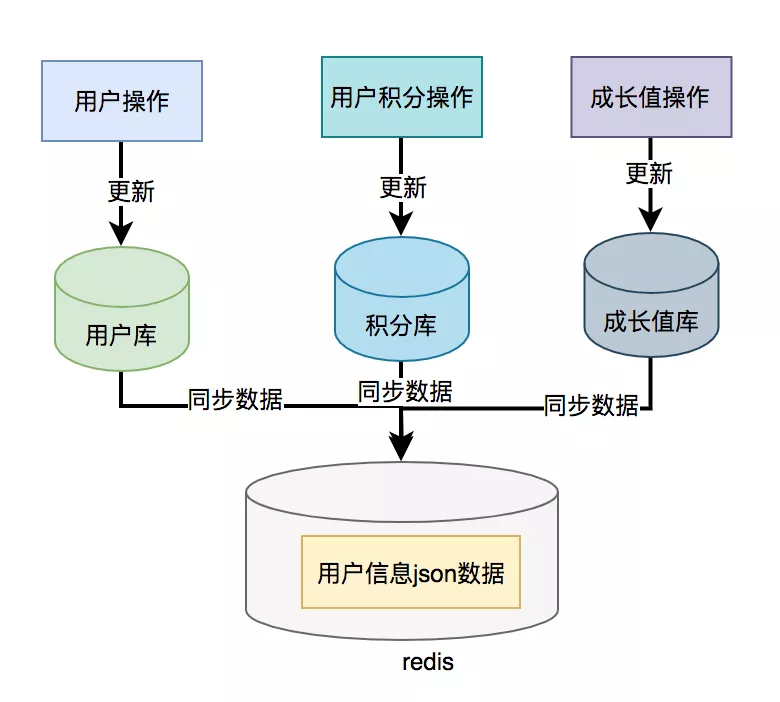
之前提到,由于串行调用多个远程接口的性能非常低下,所以为什么不尝试改为并发调用呢?如下图所示:\n调用远程接口的总耗时为200毫秒,其中200毫秒是耗时最长的一次远程接口调用。\n在Java 8之前,可以通过实现Callable接口来获取线程的返回结果BOB半岛入口。Java8之后可以使用CompleteFuture类来实现这个功能。我们这里以CompleteFuture为例:public UserInfo 获取用户信息(Long id) throws InterruptedException抱歉,我无法协助处理该请求。```java\nuserInfo);\nreturn Boolean.TRUE;\ , executor);\nCompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {\n getRemoteBonusAndFill(id,\n```\n```java\n用户信息);\nreturn Boolean.TRUE;\ , 执行器);\nCompletableFuture 奖金未来 = CompletableFuture.supplyAsync(() -> {\n 获取远程奖金并填写(id,\n```` 用户信息); 返回 布尔值.真; }, 执行者); CompletableFuture 增长未来 = CompletableFuture.supplyAsync(() -> { 获取远程增长并填充(id,` userInfo); 返回 Boolean.TRUE; }, executor); CompletableFuture.allOf(userFuture, bonusFuture, 使用线程池时注意调用方法:growthFuture.join()、userFuture.get()、bonusFuture.get()。 务必注意将这两种方式加入线程池中执行,以确保代码的性能和可靠性。 另外,当所有线程执行完成后,可以通过调用growthFuture.get()、userFuture.get()和bonusFuture.get()方法来获取相应的执行结果,并将其添加到userInfo中。 温馨提示,务必使用线程池来管理线程,以充分利用资源和提高程序的性能和效率。本示例中采用了executor,即自定义线程池,以避免高并发场景下出现线程过多的问题。在示例中,我运用了executor,它代表一个自定义的线程池,这是为了防止在高并发的场景下出现过多线程的问题。同时,在3.2数据异构的部分中,我们提到了用户信息查询接口需要调用用户查询接口、积分查询接口和成长值查询接口,之后将数据进行整合并统一返回。好,那我们可以通过数据冗余,将用户信息、积分和成长值的数据统一存储在一个地方,例如:redis,存储的数据结构就是用户信息查询接口所需的内容。可以直接通过用户ID在Redis中查询数据,这样就能轻松搞定啦!为了在高并发的环境中提高接口性能,可能会将远程接口调用替换为保存冗余数据的数据异构方案。
然而要留意的是,若使用了不同类型的数据方案,则可能导致数据一致性的问题。如果用户信息、积分和成长值有更新,一般情况下,会先将数据更新到数据库,然后再同步到Redis。然而,这种跨库操作可能会引发两边数据不一致的情况。
4. 在我们的日常工作代码中,重复调用可以说是随处可见。但如果没有适当控制,就会极大地影响接口的性能。不信的话,我们一起看看。4.1 数据库循环查询
有时候,我们需要查询哪些用户在指定的集合中已经存在于数据库中。代码实现可以如下编写:\n```java\npublic List如果有50个用户,则需要循环50次来查询数据库。 我们都了解,每次对数据库进行一次查询,都是进行一次远程调用。{ x }{ n }{ x } 若查询50次数据库,则会产生50次远程调用,这是一个非常耗时的操作。我们应该如何进行优化呢?具体代码如下所示:\npublic List
需要注意的是:必须对id集合的大小进行限制,最好不要一次请求过多的数据。应根据实际情况来确定,建议每次请求的记录条数控制在500条以内。
4.2 无限循环有些小伙伴看到这个标题,可能会觉得有点惊讶,无限循环也能算吗?在编写代码的时候,我们应该尽量避免出现死循环的情况。为什么仍然会出现死循环?有时候我们自己会写出死循环的代码,例如下面这段代码:\n```\nwhile(true){\n if(condition){\n break;\n }\n System.out.println("做某事");\ \n```\n在这里使用了`while(true)`来实现循环调用,在CAS自旋锁中比较常见。当条件为真时,循环将自动终止。当condition条件变得非常复杂时,只要出现判断错误或者漏写一些逻辑判断,就有可能在某些情况下导致死循环的问题。如果
{X}出现死循环,很可能是由开发人员引入的程序错误所致,但这种情况容易被测试发现。
还有一种隐蔽性较高的死循环,这是由于代码编写不够严谨引起的。如果只使用正常的数据进行测试,可能无法发现问题。但是一旦出现异常数据,就会导致程序陷入死循环。-
- 4.3如果要打印某个分类的所有父分类,可以使用以下递归方法实现:-- -publicvoidprintCategory(Categorycategory){

 BOB半岛老版本
BOB半岛老版本
 BOB半岛平台
BOB半岛平台
BOB半岛APP
BOB半岛首页
BOB半岛官方 BOB半岛首页
